音视频设备数据流分析
少于1分钟
关键节点介绍
Input:
HDMI/SDI Camera or PC Desktop Captured Video
Output:
HDMI/SDI Monitor or PC Display
主控芯片:MPU
Rockchip RK3568
NXP i.MX8M Plus
Encode IP Module
Decode IP Module
宏观层面的数据流走向(把MPU看做一个黑盒Blackbox):
Input直接进入MPU,MPU将进来的数据进行编码,然后放进内存中
从软件层面看,早期的Framebuffer方式显示,是开辟一块内存区,将编码后的数据进行解码,解码后的数据拷贝到特定的内存区中, 相应的显示设备上就有了内存区域中的相关显示内容了。
其实,这里还有非常重要的核心问题:
如果没有编码,就不需要解码,直接发到内存里,既显示速度快,又便宜。省去了编解码器,肯定有一定的成本下降。 这个的确很重要,坦白说,我也没有系统的去研究过,所以为了聚焦本文的重点,也为了有尽可能权威的回答,我另外开一篇来说。
本文主要是介绍宏观微观视角下的数据流走向。 而接下来,我们就要进入微观层面了
微观层面的数据流走向(进入MPU内部)
Simple Scene
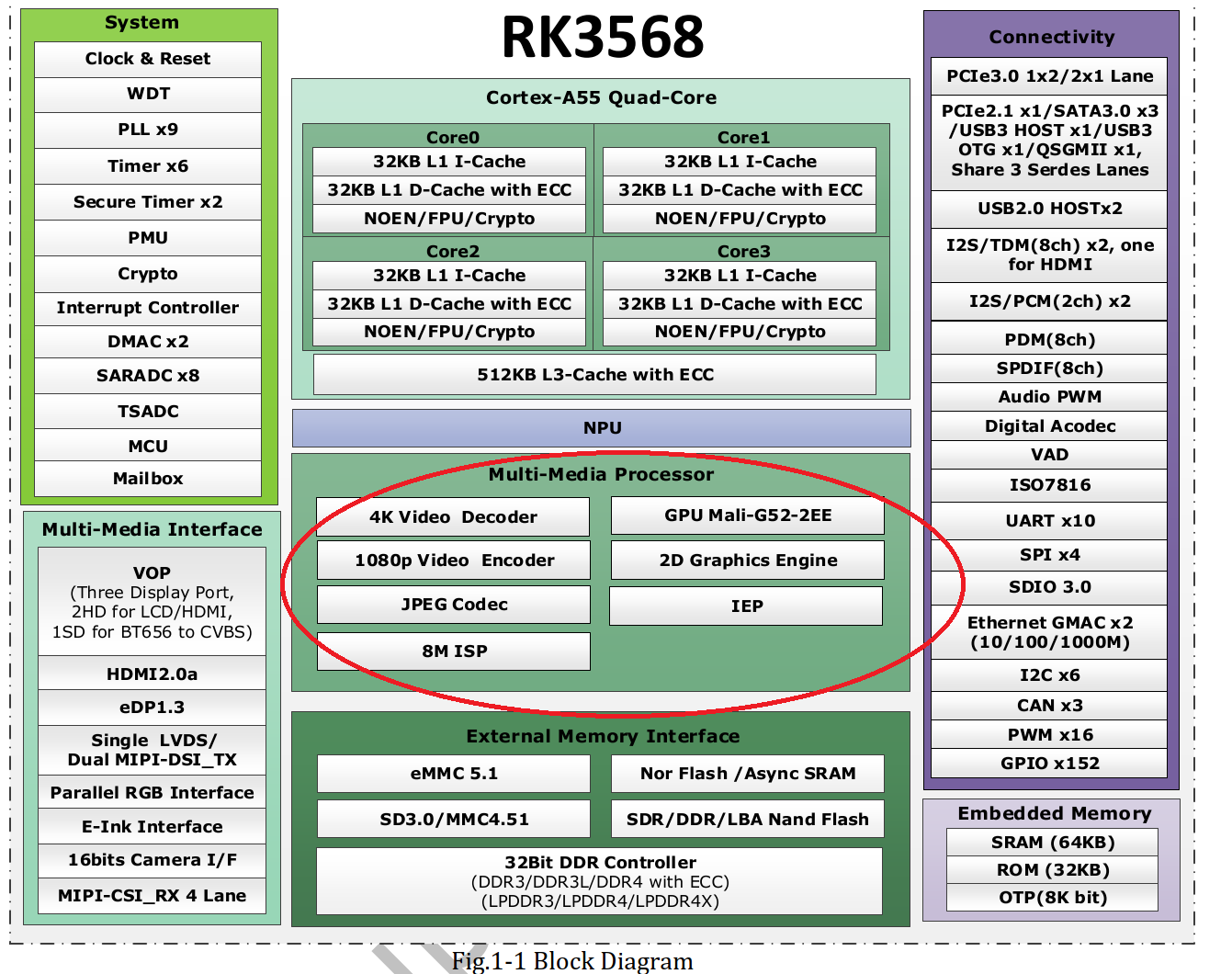
这里,特别看红色圈住的区域。
这里面至少有GPU/Decoder/Encoder等7个模块,站在Soc(System On Chip)片上系统的角度来看,他们都是独立的IP核心(Intellectual Property)
IP的中文叫知识产权(至于这里为什么叫这么一个名字,是因为每一个IP都是设计好的,能够直接被拿来使用的,因此命名为知识产权。并非中文世界所认为的是一种无形资产而已)。
关于IP所处的整个产业链的位置,我借鉴了抖音号(ICshow),名为(芯片工程师阿伟「芯片设计服务」)的图。因为我认为,要了解一个新的术语,需要放在整个立体的产业结构中去看,这样最容易准确抓住它的定义,即便短期内没法下准定义,但是起码朦胧的认识已经有了。
图如下
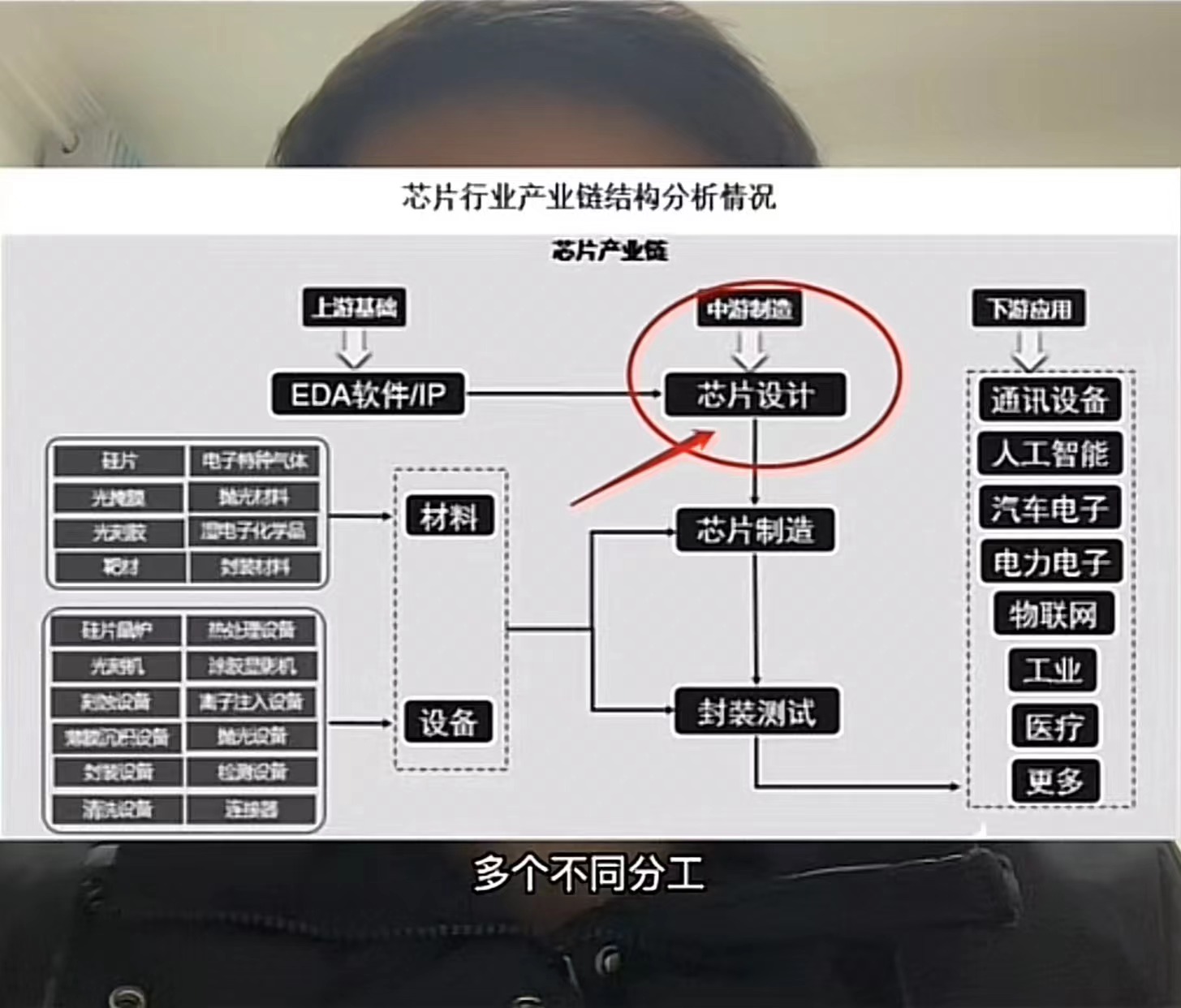
也就是说MPU要对外实现编解码功能、图形渲染等图形处理单元的功能,是靠内部的IP来提供。
MPU内部的IP Cores之间倚靠总线(总线的详细知识点后期我会进一步补充)进行连接。
从ASIC的英文全称来看,它的定义是特殊应用的集成电路。因此,它最大的特点是:一旦制造出来,它的结构是不可以重新设计或调整的。正因为这样,我们可以把MPU当成一个大的ASIC。(RISC-V的特殊性,可扩展指令,在此,我们先把它剔除在该分类之外)
在MPU这个ASIC里面,有众多的IP Cores。当Input有数据接入MPU,会先进行简单的图像处理(模拟信号转换成数字信号等)。然后送到VPU这个IP里面,VPU内部又有编码器和解码器以及缓存,可以对输入进来的信号进行编码,从RGB这样的显示格式转换成H.264这样的数字格式。
编码后,会经过高速数据总线(AXI)传输到内存里。(因为高清HD甚至超高清UHD的视频传输,经过总线和内存,因此,内存的带宽和总线的带宽是重要的参数,是否会成为瓶颈,这里必须要关注。)
之后,若需要显示在mpu的hdmi output interface上,还需要将已经编码的数据再次解码成为RGB或YUV这样的图像数据。 也可以将编码后的数据透过ethernet或usb等interface发出去。
Complex Scene
在一个更复杂的场景下,例如同时有16路camera接入mpu,这个时候,vpu本身的编码能力再强大,也无法进行实时的编码了。 这个时候,就要考虑使用外接的编码器了。
例如,使用某一些为16路(或者更多路数)的信号接入进行并行计算的ASIC,这些ASIC可以以低功耗、低延迟的效果进行加速的计算,进而取代mpu原先内置的vpu。
或者还有第二种办法,就是用可编程逻辑门阵列,就是FPGA。它能够灵活的设计电路结构,为某一种算法适配其加速功能。不足之处是功耗大,而且功能较多,有文章说:FPGA是通用可编辑的芯片,冗余功能比较多。不管你怎么设计,都会多出来一些部件。
详细的关于FPGA和ASIC的对比,请看Reference的文章1.到底什么是ASIC和FPGA?
总结
从内部来看MPU,是必须的,这样才能深刻去查看研究data sheet里面的block diagram到底想要表达什么,有多少module。 从SOC的角度看IP core,看总线,看ASIC,看FPGA,进而看GPU,NPU, CPU,似乎它是一条线,把这些零散的概念,串起来了。 感谢上帝。